Scaleout Systems: Vad är edge computing och varför är det viktigt i militärt beslutsfattande?

Edge computing och operativ förmåga
Utmaningar med edge computing
Det finns flera kritiska utmaningar finns vid implementering av datorseendesystem i distribuerade miljöer vid edge computing.
- Datasekretess och säkerhet: Att centralisera känslig bilddata för modellträning väcker allvarliga integritetsfrågor, problem med regelverk och säkerhetsrisker. I många fall kan organisationer inte fritt flytta data från kant-enheter till centrala träningssystem på grund av juridiska eller säkerhetsmässiga begränsningar.
- Nätverksbegränsningar: Att överföra stora mängder bilddata från distribuerade kant-enheter till centrala servrar är ofta opraktiskt på grund av begränsad bandbredd i avlägsna eller mobila miljöer, oregelbunden uppkoppling samt höga kostnader för dataöverföring via mobil- eller satellitnät.
- Hårdvaruvariation: Kant-enheter har varierande beräkningskapacitet, från enkla sensorer till kraftfulla enheter för kantberäkningar. Denna variation gör det svårt att tillämpa enhetliga tränings- och inferensstrategier över hela enhetsflottan.
- Krav på kontinuerlig anpassning: Datorseendemodeller behöver kontinuerligt finjusteras när miljön förändras och nya visuella mönster uppstår. Traditionella metoder saknar ofta effektiva mekanismer för kontinuerligt lärande utan att hela modellen behöver tränas om.
- Begränsad mängd märkta data: Organisationer har ofta gott om rå bilddata men brist på korrekt märkt data, vilket skapar en flaskhals i utvecklingen av träffsäkra och robusta datorseendemodeller med traditionella övervakade metoder.
Metoder för edge computing
Flera tekniska metoder har utvecklats för att hantera dessa utmaningar, däribland federeralt lärande för datorseende. Federerat lärande möjliggör modellträning över distribuerade enheter utan att rådata behöver centraliseras. För datorseendetillämpningar innebär detta flera fördelar. Modeller kan tränas direkt på kant-enheter medan bilddata förblir lokal, endast modellparametrar (inte bilder) utbyts med centrala servrar och organisationer kan utnyttja stora mängder distribuerad data med bibehållen integritet. Träning kan också ske över heterogen hårdvara med optimerade protokoll
Självövervakat inlärning
Självövervakade (self-supervised) metoder minskar beroendet av märkta data genom att:
- Förträna visuella modeller med omärkta bilder
- Skapa robusta funktionsrepresentationer anpassade till operativa miljöer
- Utveckla grundmodeller som kan finjusteras med ett fåtal märkta exempel
- Underlätta effektiv kunskapsöverföring mellan relaterade visuella uppgifter
Kontinuerliga inlärningssystem
Moderna system för datorseende vid kanten innehåller mekanismer för kontinuerlig förbättring:
- Aktiva inlärningsflöden som väljer ut de mest värdefulla bilderna för märkning
- “Human in the loop” system för att effektivt integrera expertfeedback
- “Experience replay” och andra metoder för att undvika katastrofal glömska
- Möjlighet till personalisering för enhetsspecifik anpassning
Nätverkseffektiv träning
För att minimera bandbreddsbehov använder systemen:
- Modellcentrerad snarare än datacentrerad kommunikation
- Asynkrona träningsprotokoll för enheter med oregelbunden uppkoppling
- Komprimering av modelluppdateringar för att minska överföringsvolym
- Träningsflöden som tillåter frånkoppling och återanslutning vid instabil uppkoppling
Hårdvaruoptimerade implementationer
För att hantera varierande hårdvara krävs:
- Träningsstrategier anpassade till vanliga kant-plattformar (t.ex. Nvidia Jetson)
- Adaptiv beräkning beroende på tillgängliga resurser
- Modell-destillering för att köra effektiva modeller på begränsade enheter
- Optimering från träning till inferens på samma hårdvara
Integritetsskyddande arkitekturer
För att möta krav på dataskydd och efterlevnad används:
- Lokal datahantering som håller känslig bilddata på ursprungsenheten
- Arkitekturer där endast parametrar utbyts
- Inbyggda verktyg för riskbedömning av integritetsläckor
- Möjligheter till differentiell integritet för matematiska garantier
Tillämpningar inom olika branscher
Datorseende vid kanten används i en rad olika områden:
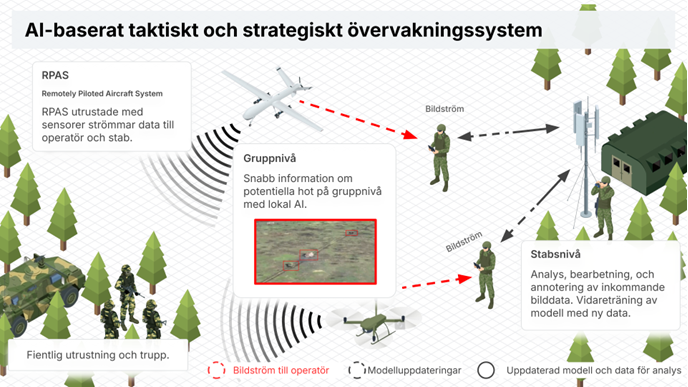
- Försvar & säkerhet: Kant-baserad visuell intelligens förstärker övervakning, drönarsystem och säkerhetsinstallationer, med strikt kontroll över dataintegritet och minimerad signalexponering.
- Industriell IoT & automation: Distribuerad kvalitetskontroll och prediktivt underhåll gör det möjligt att genomföra visuell inspektion på flera fabriker utan att avslöja känslig produktionsdata.
- Fordon & mobilitet: Fordonsflottor kan gemensamt lära sig från varierande körförhållanden utan att exponera data, vilket påskyndar utvecklingen av autonoma och assisterade körsystem.
- Smarta städer & infrastruktur: Integritetssäkra övervakningssystem stödjer trafikstyrning, folkmängdsanalys och infrastrukturövervakning, med efterlevnad av dataskyddsregler och minimerade bandbreddsbehov.